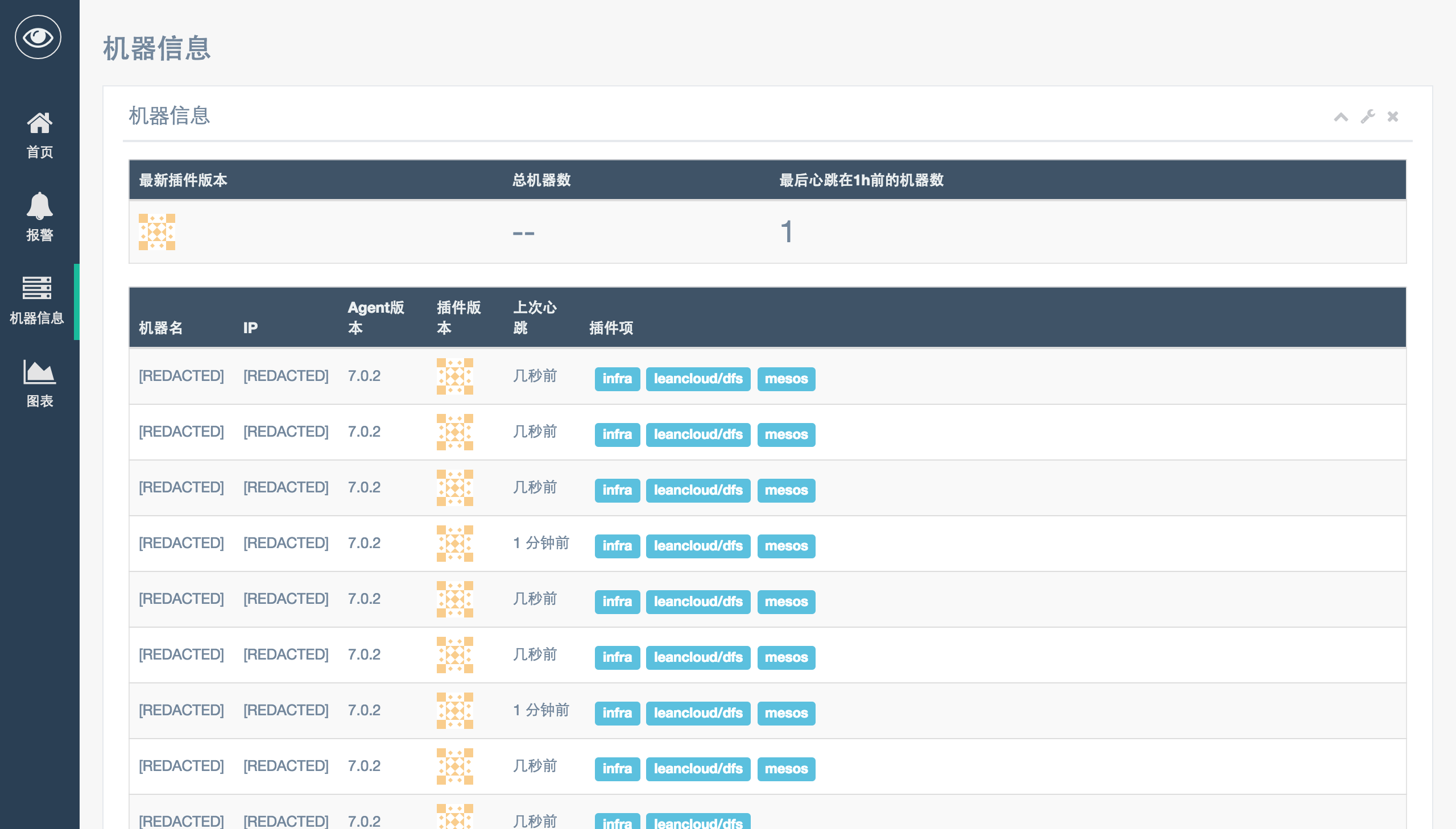
基本情况¶
起初在 LeanCloud 内部是直接使用了 Open-Falcon 。 后续的使用过程中因为自己的需求做了大量修改,然后开源。
设计思路¶
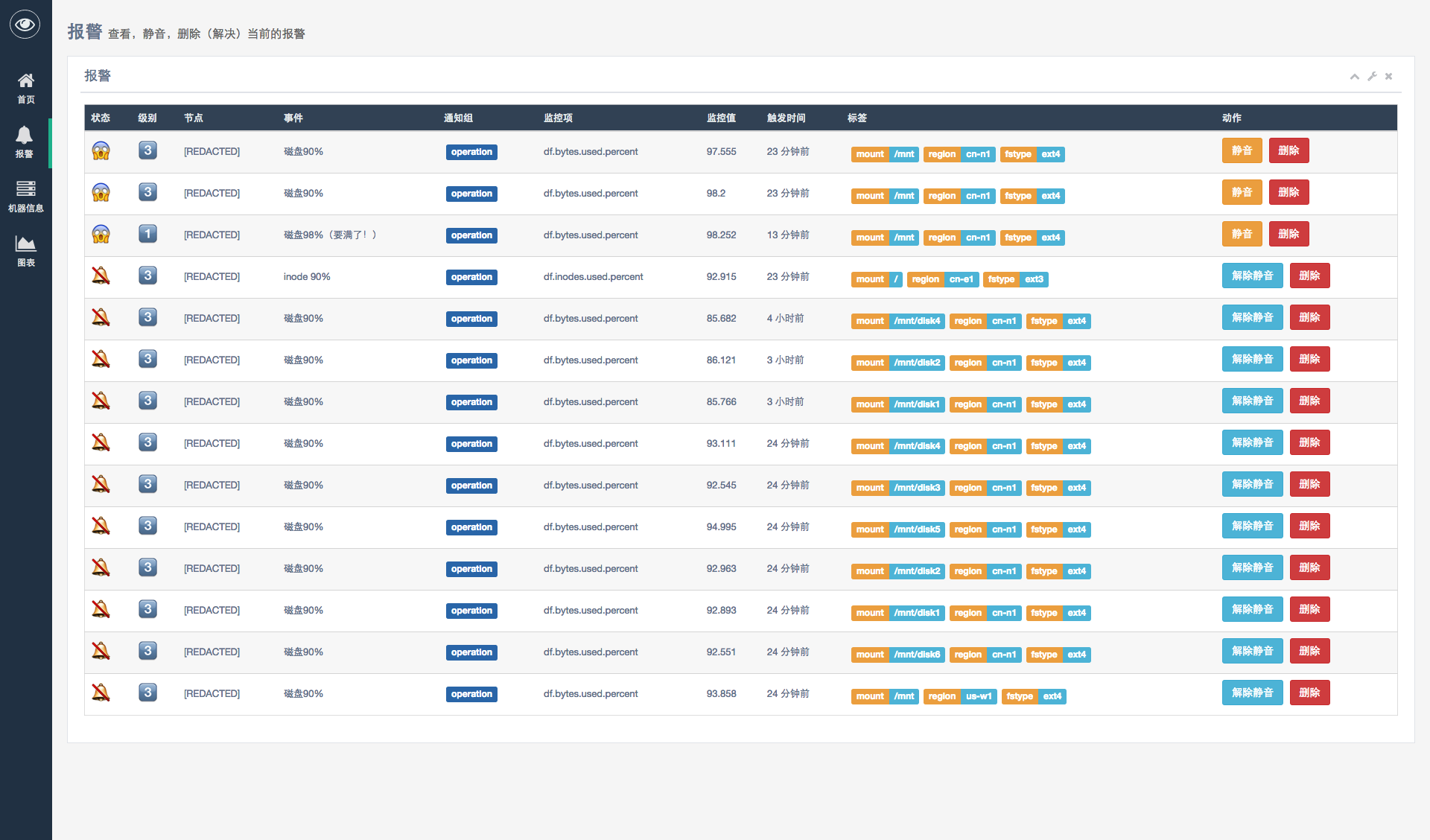
Satori 希望最大程度的减少监控系统的部署维护难度。如果在任何的部署、增删维护报警的时候觉得好麻烦,那么这是个 bug。
监控时的需求很多样,Satori 希望做到『让简单的事情简单,让复杂的事情可能』。常用的监控项都会有模板,可以用 Copy & Paste 解决。略复杂的监控需求可以阅读 riemann 的文档,来得知怎么编写复杂的监控规则。
因为 LeanCloud 的机器规模不大,另外再加上现在机器的性能也足够强劲了,所以放弃了 Open-Falcon 中横向扩展目标。如果你的机器数量或者指标数目确实很大,可以将 transfer、 InfluxDB、 riemann 分开部署。这样的结构支撑 5k 左右的节点应该是没问题的。
在考察了原有的 Open-Falcon 的架构后,发现实质上高可用只有 transfer 实现了,graph、judge 任何一个实例挂掉都会影响可用性。对于 graph,如果一个实例挂掉的话,还必须要将那个节点恢复,不能通过新加节点改配置的方式来恢复;judge 尽管可以起新节点,但是还是要依赖外部的工具来实现 failover,否则是需要修改 transfer 的配置的。因此 Satori 中坚持用单点的方式来部署,然后通过配合公网提供的 APM 服务保证可用性。真的希望有高可用的话,riemann 和 alarm 可以部署两份,通过 keepalived 的方式来实现,InfluxDB 可以官方的 Relay 来实现。
架构图¶
![digraph Architecture {
{
rank=same;
"用户" [shape=doublecircle];
"机器" [shape=doublecircle];
}
"规则仓库" [shape=rect];
InfluxDB [shape=cylinder];
"用户" -> "规则仓库" [label="修改"];
"规则仓库" -> {riemann alarm} [label="触发更新"];
"用户" -> alarm [label="查看报警"];
"用户" -> Grafana [label="查看指标"];
Grafana -> InfluxDB [label="请求数据"];
"机器" -> agent -> transfer -> {InfluxDB riemann} [label="监控指标"];
riemann -> alarm [label="生成报警"];
alarm -> {SMS Mail "微信"};
riemann -> master -> agent [label="下发插件参数"];
agent -> master [label="心跳"];
master -> transfer [label="报告 agent 存活"];
}](../_images/graphviz-6eab8ea2775ee1adb852eab4d405755cdc13df6c.png)
与 Open-Falcon 的比较¶
| Satori | Open-Falcon | |
|---|---|---|
| agent |
|
可以单机部署 |
| transfer | 可以配合原版 graph 和 judge 运行 | |
| alarm |
|
支持报警合并 |
| sender | 已经合并进了 alarm 中 | |
| links | 移除了 [4] | |
| graph | 替换成 InfluxDB 了 | |
| query | 移除了 | |
| dashboard | 替换成 Grafana 了 | |
| task | InfluxDB 自带 task 的功能 | |
| aggreagator | 规则中有 aggregate 和 slot-window 实现相同功能 | |
| nodata | 规则中有 watchdog 实现相同功能 | |
| portal | 移除了,所有信息通过规则仓库管理 | |
| gateway | 合并进了 transfer | |
| master | 没有数据库依赖 | 在 Open-Falcon 叫 hbs |
| portal | 移除了,所有信息通过规则仓库管理 | |
| frontend | 完全重写,采用了纯前端的方案 | 对应 Open-Falcon 中的 fe |
| InfluxDB | 开源组件,用来存储和查询收集上来的监控信息 | Open-Falcon 中不存在 |
| riemann | 开源组件,负责报警判定和产生插件规则 | Open-Falcon 中不存在 |
| Grafana | 开源组件,替换了 graph | 对应 Open-Falcon 中的 dashboard |
| nginx | 为前端页面提供服务 | Open-Falcon 中不存在 |
| [1] | 使用了 hitripod 的补丁 |
| [2] | 即 Open-Falcon 中 gateway 的功能 |
| [3] | 电话、短信、BearyChat、OneAlert、PagerDuty、邮件、微信企业号 |
| [4] | 推荐直接使用低优先级的通道(如 BearyChat/其他IM,或者 BitBar), 或者在规则中做聚合(参见 复杂需求 ),不做报警合并。 |
注解
与 Open-Falcon 的比较是基于 v0.1 的,很多东西对 Falcon-Plus 不再适用了